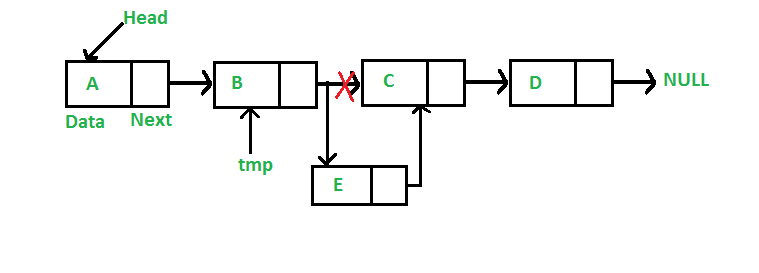
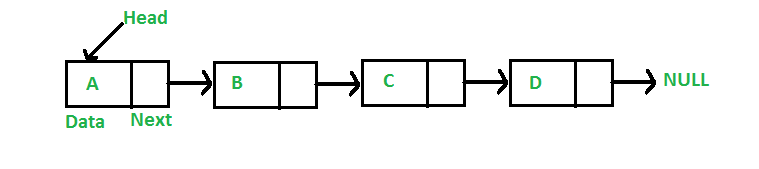
变形一个 SortedMerge() 函数,带有两个链表参数, 每个链表都是按照升序排列, 然后把这两个链表合并成一个升序的链表。 SortedMerge() 应该返回一个全新的链表。新链表应该把两个链表的结点拼接起来。
例如第一个链表是 5->10->15 第二个链表是 2->3->20, 然后 SortedMerge() 应该返回 2->3->5->10->15->20.
有很多情况需要处理: ‘a’ 或者 ‘b’ 可能为空, 处理 ‘a’ 或 ‘b’ 过程中可能首先跑完某个, 最后的问题是开始结果是空, 然后通过‘a’ 和 ‘b’ 把它建立起来。
方法 1 (使用仿制结点)
这里的策略是使用一个临时的仿制结点,作为结果链表的开始。Tail 指针总是表示结果链表的最后一个结点, 所以添加新结点很容易。
在结果链表是空的时候,仿制结点会给尾部指针一些指向作为初始化。仿制结点是有效的, 因为它只是临时的, 而且它在栈内分配。循环进行, 从 ‘a’ 或者 ‘b’ 移除一个结点, 然后添加到尾部。当完事后,结果就保存在 dummy.next.
/* C/C++ program to merge two sorted linked lists */
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
/* Link list node */
struct Node
{
int data;
struct Node* next;
};
/* pull off the front node of the source and put it in dest */
void MoveNode(struct Node** destRef, struct Node** sourceRef);
/* Takes two lists sorted in increasing order, and splices
their nodes together to make one big sorted list which
is returned. */
struct Node* SortedMerge(struct Node* a, struct Node* b)
{
/* a dummy first node to hang the result on */
struct Node dummy;
/* tail points to the last result node */
struct Node* tail = &dummy;
/* so tail->next is the place to add new nodes
to the result. */
dummy.next = NULL;
while (1)
{
if (a == NULL)
{
/* if either list runs out, use the
other list */
tail->next = b;
break;
}
else if (b == NULL)
{
tail->next = a;
break;
}
if (a->data <= b->data)
MoveNode(&(tail->next), &a);
else
MoveNode(&(tail->next), &b);
tail = tail->next;
}
return(dummy.next);
}
/* UTILITY FUNCTIONS */
/* MoveNode() function takes the node from the front of the
source, and move it to the front of the dest.
It is an error to call this with the source list empty.
Before calling MoveNode():
source == {1, 2, 3}
dest == {1, 2, 3}
Affter calling MoveNode():
source == {2, 3}
dest == {1, 1, 2, 3} */
void MoveNode(struct Node** destRef, struct Node** sourceRef)
{
/* the front source node */
struct Node* newNode = *sourceRef;
assert(newNode != NULL);
/* Advance the source pointer */
*sourceRef = newNode->next;
/* Link the old dest off the new node */
newNode->next = *destRef;
/* Move dest to point to the new node */
*destRef = newNode;
}
/* Function to insert a node at the beginging of the
linked list */
void push(struct Node** head_ref, int new_data)
{
/* allocate node */
struct Node* new_node =
(struct Node*) malloc(sizeof(struct Node));
/* put in the data */
new_node->data = new_data;
/* link the old list off the new node */
new_node->next = (*head_ref);
/* move the head to point to the new node */
(*head_ref) = new_node;
}
/* Function to print nodes in a given linked list */
void printList(struct Node *node)
{
while (node!=NULL)
{
printf("%d ", node->data);
node = node->next;
}
}
/* Drier program to test above functions*/
int main()
{
/* Start with the empty list */
struct Node* res = NULL;
struct Node* a = NULL;
struct Node* b = NULL;
/* Let us create two sorted linked lists to test
the functions
Created lists, a: 5->10->15, b: 2->3->20 */
push(&a, 15);
push(&a, 10);
push(&a, 5);
push(&b, 20);
push(&b, 3);
push(&b, 2);
/* Remove duplicates from linked list */
res = SortedMerge(a, b);
printf("Merged Linked List is: \n");
printList(res);
return 0;
}
#
输出 :
Merged Linked List is:
2 3 5 10 15 20
方法 2 (使用本地引用)
这个方案在结构上跟上面的很相似, 但是它没有使用仿制结点。替代方案是, 它维护了一个结构体 node** 指针, lastPtrRef 这指针总是指向结果链表的最后一个结点。这个方式解决了仿制结点解决的问题 — 处理了结果链表为空的情况。
struct Node* SortedMerge(struct Node* a, struct Node* b)
{
struct Node* result = NULL;
/* point to the last result pointer */
struct Node** lastPtrRef = &result;
while(1)
{
if (a == NULL)
{
*lastPtrRef = b;
break;
}
else if (b==NULL)
{
*lastPtrRef = a;
break;
}
if(a->data <= b->data)
{
MoveNode(lastPtrRef, &a);
}
else
{
MoveNode(lastPtrRef, &b);
}
/* tricky: advance to point to the next ".next" field */
lastPtrRef = &((*lastPtrRef)->next);
}
return(result);
}
方法 3 (使用递归)
递归的代码比迭代代码更加清晰。你可能不太想使用递归方法,因为它会随着链表的长度成比例的使用栈空间。
struct Node* SortedMerge(struct Node* a, struct Node* b)
{
struct Node* result = NULL;
/* Base cases */
if (a == NULL)
return(b);
else if (b==NULL)
return(a);
/* Pick either a or b, and recur */
if (a->data <= b->data)
{
result = a;
result->next = SortedMerge(a->next, b);
}
else
{
result = b;
result->next = SortedMerge(a, b->next);
}
return(result);
}