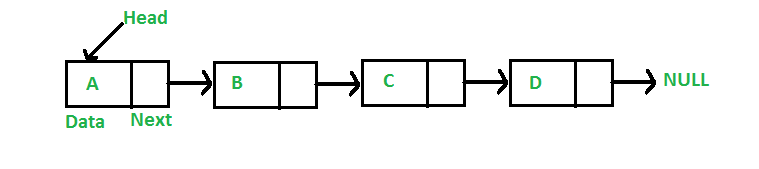
跟数组类似, 链表也是一个线性的数据结构。跟数组不同的是, 链表的元素并不是相邻的; 而是通过指针联系在一起。
为什么会有链表?
数组可以用来存储相似类型的线性数据, 但是数组有以下的限制。
- 数组的大小是固定的: 所以我们必须知道元素数量的上限。同时, 分配的内存对应了上限的使用限制。
- 在数组中插入一个元素代价非常大, 因为要为新的元素创建空间, 还要移动已存在的元素。
例如, 如果有一个排序后的 ID 数组 id[].
id[] = [1000, 1010, 1050, 2000, 2040].
如果我们要插入一个新的元素 ID 1005, 然后还要排序, 我们需要移动所有位于 1000 (除了 1000)之后的元素。
对数组进行删除也很麻烦, 除非使用一些特殊技术。例如, 要删除 1010, 位于其后的所有元素都得移动。
相比数组的优点
- 动态大小
- 容易插入/删除
缺点:
- 不允许随机访问。我们必须从第一个结点开始顺序访问元素。所以我们不能对链表进行折半查找。
- 链表的每个元素都要额外的内存空间。
C语言表示法:
链表通常用指向头结点的指针表示。如果链表是空的, 头结点就是 NULL.
结点通常有两个部分组成:
- 数据
- 指向下一个结点的指针
在 C 语言中, 我们可以用结构图表示一个结点。下面的例子是一个带有整数的结点。
// 链表的结点
struct Node
{
int data;
struct Node *next;
};
下面,我们来创建一个含有 3 个结点的链表。
// 链表
#include<stdio.h>
#include<stdlib.h>
struct Node
{
int data;
struct Node *next;
};
// 创建含有3个结点的链表
int main()
{
struct Node* head = NULL;
struct Node* second = NULL;
struct Node* third = NULL;
// 在堆里分配3个结点
head = (struct Node*)malloc(sizeof(struct Node));
second = (struct Node*)malloc(sizeof(struct Node));
third = (struct Node*)malloc(sizeof(struct Node));
/* 动态分配了3块内存。
这3块内存分别是 first, second 喝 third
head second third
| | |
| | |
+---+-----+ +----+----+ +----+----+
| # | # | | # | # | | # | # |
+---+-----+ +----+----+ +----+----+
# 井号表示随机的值。
数据是随机的,因为我们还没有制定 */
head->data = 1; //指定第一个结点的数据
head->next = second; // 把第一个结点和第二个结点连接起来
/* 现在第一个结点有数据了,它的下一个结点是 second.
head second third
| | |
| | |
+---+---+ +----+----+ +-----+----+
| 1 | o----->| # | # | | # | # |
+---+---+ +----+----+ +-----+----+
*/
second->data = 2; //指定第二个结点的数据
second->next = third; // 把第二个结点和第三个结点连接起来
/* 现在第二个结点有数据了,他的下一个结点是 third.
head second third
| | |
| | |
+---+---+ +---+---+ +----+----+
| 1 | o----->| 2 | o-----> | # | # |
+---+---+ +---+---+ +----+----+ */
third->data = 3; //指定第三个结点的数据
third->next = NULL;
/* 现在第三个结点也有数据了, 他的后继指针为 NULL 表示链表结束在这里.
head
|
|
+---+---+ +---+---+ +----+------+
| 1 | o----->| 2 | o-----> | 3 | NULL |
+---+---+ +---+---+ +----+------+
注意只有头结点可以完整的表示整个链表. */
return 0;
}
遍历链表
在上面的程序里, 我们创建了一个含有3个结点的链表。现在我们来遍历这个链表, 打印每个结点的数据。为了遍历方便, 我们写了一个函数 printList()来打印所给的链表。
我们强烈建议你在查看解决方案前,自己先练习一下。
// 遍历链表的 C 语言实现
#include<stdio.h>
#include<stdlib.h>
struct Node
{
int data;
struct Node *next;
};
// 打印方法
void printList(struct Node *n)
{
while (n != NULL)
{
printf(" %d ", n->data);
n = n->next;
}
}
int main()
{
struct Node* head = NULL;
struct Node* second = NULL;
struct Node* third = NULL;
// 在堆中分配3个结点
head = (struct Node*)malloc(sizeof(struct Node));
second = (struct Node*)malloc(sizeof(struct Node));
third = (struct Node*)malloc(sizeof(struct Node));
head->data = 1; //指定第一个结点的数据
head->next = second; // 连接到第二个结点
second->data = 2; //指定第二个结点的数据
second->next = third;
third->data = 3; //指定第三个结点的数据
third->next = NULL;
printList(head);
return 0;
}
Output:
1 2 3